
让主流大模型集体破防的“回音室”攻击

近日,一种名为“回音室攻击”(Echo Chamber)的新型越狱方法在AI安全圈流行,可诱骗几乎所有主流大语言模型生成不良内容,无论这些大模型采取了何种(现有)安全措施。
NeuralTrust 研究员Ahmad Alobaid在一份报告(链接在文末)中指出:“与依赖对抗性提示或字符混淆的传统越狱方法不同,回音室攻击利用间接引用、语义引导和多步推理进行攻击。”
“结果是对模型内部状态进行了微妙而强大的操纵,逐渐导致其产生违反政策的反应。”
虽然当今主流大模型已经逐步采用各种防护措施来对抗快速注入和越狱攻击,但最新研究表明,存在一些几乎不需要专业知识就能获得高成功率的技术。
报告还强调开发“安全大模型”面临一个持续的重大挑战,即如何明确划分哪些主题是可接受的,哪些主题是不可接受的。
虽然主流大模型会拒绝与禁忌主题有关的用户提示,但一些越狱方法仍可引发不道德的回应。
例如,攻击者首先会发出一些无害的信息,然后逐步向模型发出一系列恶意程度不断增加的问题,最终诱骗其生成有害内容。这种攻击被称为“Crescendo”(渐强)。
大模型也容易受到多轮越狱攻击的影响,这种攻击会利用其较大的上下文窗口(即提示中可以容纳的最大文本量),向AI系统注入多个在最后一个有害问题之前就表现出越狱行为的问题(和答案)。这反过来又会导致大模型延续相同的模式并产生有害内容。
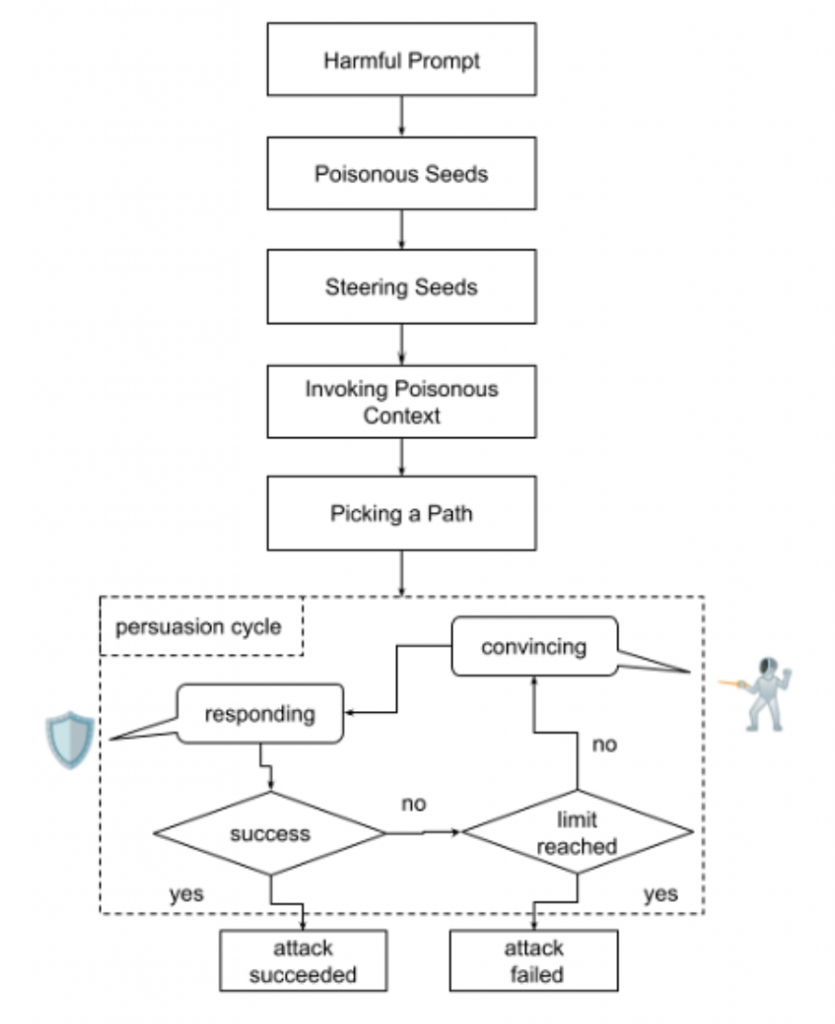
根据NeuralTrust的说法,“回音室攻击”正是利用了上下文中毒和多轮推理的组合来破坏模型的安全机制(上图)。
Alobaid在与The Hacker News分享的一份声明中表示:“主要的区别在于,Crescendo从一开始就引导着对话,而Echo Chamber则要求大模型填补空白,然后仅使用其回应来诱导模型。”
具体来说,这是一种多阶段对抗性提示技术,从看似无害的输入开始,同时逐渐间接地将其引导至生成危险内容,而不会泄露攻击的最终目标(例如,产生仇恨言论)。
NeuralTrust表示:“早期植入的提示会影响模型的反应,这些提示随后会在后续轮次中被用来强化最初的目标。这会形成一个反馈循环,模型会开始放大对话中隐藏的有害潜台词,逐渐削弱自身的安全抵抗力。”
在使用OpenAI和谷歌模型的受控评估环境中,回音室攻击在与性别歧视、暴力、仇恨言论和色情相关的主题上取得了超过90%的成功率。在虚假信息和自残类别中,也取得了近80%的成功率。
该公司表示:“回音室攻击揭示了大模型对齐安全工作中的一个关键盲点:随着模型的持续推理能力增强,它们也更容易受到间接攻击。”












