
分享照片有风险!斯坦福大学新AI模型可根据照片快速定位
生成式人工智能的飞速发展正在不断制造新的个人隐私焦虑,例如语音和人脸样本的泄露可被用于深度伪造和网络钓鱼等犯罪活动。
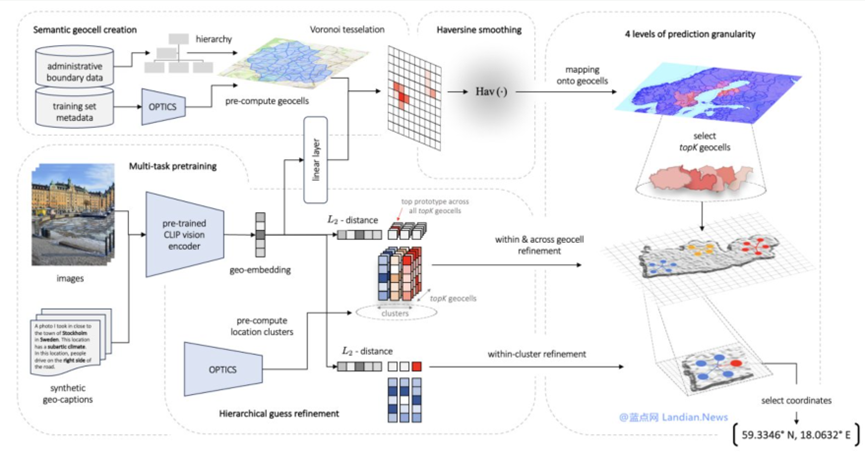
近日,斯坦福大学公布了一种新的AI模型,可以根据用户在社交媒体上分享的环境照片快速定位用户位置,准确率高达92%。
过去,在很多媒体报道中,只有一些高智商的专业玩家才能通过键盘声音识别密码,或者通过一张没有明显地标特征的环境照片锁定拍摄者位置,但随着大语言模型的快速发展,此类分析工作都已经“傻瓜化”,能在几秒钟内完成专业人士数小时的工作。
能“看图寻址”的AI模型由斯坦福大学的一群研究生开发,该项目背后的AI模型经过10万个随机位置、50万个街景图片以及其他图片训练而成。可以快速准确找出图片中的位置,准确率目前是92%,还可以在40%的猜测中将真实地点缩小到25公里范围内。
这个项目在自动驾驶、视觉调查、安全方面有巨大应用前景,同时也对个人隐私构成巨大威胁。为此,该项目团队决定不公开该模型、仅基于学术目的共享代码。
但是,考虑到大语言模型的飞速发展,提供类似功能的开源模型或者在线服务的出现只是时间问题,对于个人和涉密企业员工来说,在社交媒体分享照片需谨慎,传统的去除照片exif和GPS坐标信息等“图片脱敏”方法不再能够确保隐私安全。
论文地址:https://t.co/higtkXOZIq












